Introduction
The first web crawler was created in 1993 to measure the size of web, and they have now evolved into modern bots powered by agentic AI. Today’s internet is increasingly populated and dominated by automated AI bots that interact with applications to support AI-related tasks.
We classified AI bots into three types:
- AI scrapers, which systematically collect data from your application to train AI models.
- AI tools, which surface data from your application in AI applications using Function calling.
- AI agents, which can autonomously navigate and interact dynamically with your application to perform complex tasks.
Although some AI bots provide valuable services such as automating tedious tasks, some malicious bots can cause significant challenges for web application owners and operators. Malicious bots can overwhelm servers with excessive traffic, leading to performance degradation or even outages. Left unchecked, these bots not only compromise security but can also erode user trust and damage brand reputation.
In this post, we explore different problems caused by AI bots and learn different mechanisms to detect and manage AI bots using Amazon Web Services (AWS) WAF.
Pre-requisite
This post focuses on AWS WAF as the frontline defense to observe and manage AI bot activity against your application. If you haven’t already enabled protection with AWS WAF, then you can start by visualizing the threat landscape using AWS Shield network security director. It helps you to identify resources that are not protected with AWS WAF.
Then you can start by creating an initial security posture using one-click security integrations. It automatically creates a protection pack or web ACL with rules to protect your application from most common threats. See the following references:
- If you are using Amazon CloudFront to host your applications, then enable protection using CloudFront one-click AWS WAF integration.
- If you are using Application Load Balancer (ALB) to host your applications, then enable protection using ALB one-click AWS WAF integration.
Problems caused by AI bots
Bots are not a new threat on the web. However, the data requirements of Large Language Models (LLMs) and new interaction patterns enabled by AI agents have made bot behavior more problematic across many applications. Web applications may face the following problems caused by AI bots:
- Using proprietary data to train models: Unauthorized use of your organization’s data can create intellectual property concerns when being used to train AI models. For example, your content can be used to create potentially competing services without compensation and dilute your content’s unique market value.
- Poor performance and high costs: AI bots that are aggressively harvesting your application’s content can generate overwhelming traffic, leading to degraded performance for legitimate users. This can also incur data transfer out (DTO) charges, which wastes compute resources and potential service outages during peak scraping periods.
- Unwanted automated/agentic behavior: AI bots can automatically interact with your application without needing a human in the loop. This can take valuable human traffic away from your application because the AI can summarize its findings. AI bots can also compete with legitimate human traffic to complete high-value, time-sensitive workflows such as purchasing limited inventory. These bots generally use the following techniques to interact with your application:
-
- Function calling and AI search: AI applications use tools to search and make one-off requests for data directly from your application.
- Browser Automation Framework Interactivity: AI agents such as Amazon Nova Act use Playwright to control real browsers. They can complete multi-step tasks and interact with applications in a human-like way. These agents can execute JavaScript and handle complex UI elements effectively.
- VM-Based Interactivity: Systems such as Anthropic’s Computer Use operate within virtual machine (VM) environments. They interact with applications in a more human-like way. Unlike Playwright’s automated browsers, these systems use standard browser installations. This makes their behavior nearly indistinguishable from real human users.
Determining the scale of AI bot activity
First, you need to understand how AI bots affect your application and at what scale. Start by adding the AWS WAF Bot Control rule group to your resource protection pack with Common Inspection level. Use Count mode initially to monitor traffic patterns. This approach allows you to analyze bot activity before making changes that could impact production traffic.
The bot control common rule group verifies self-identifying bots through signature validation. It includes a CategoryAI rule that detects verified AI bots. Make sure to configure the rule group with the latest version, as shown in the following figure 1.
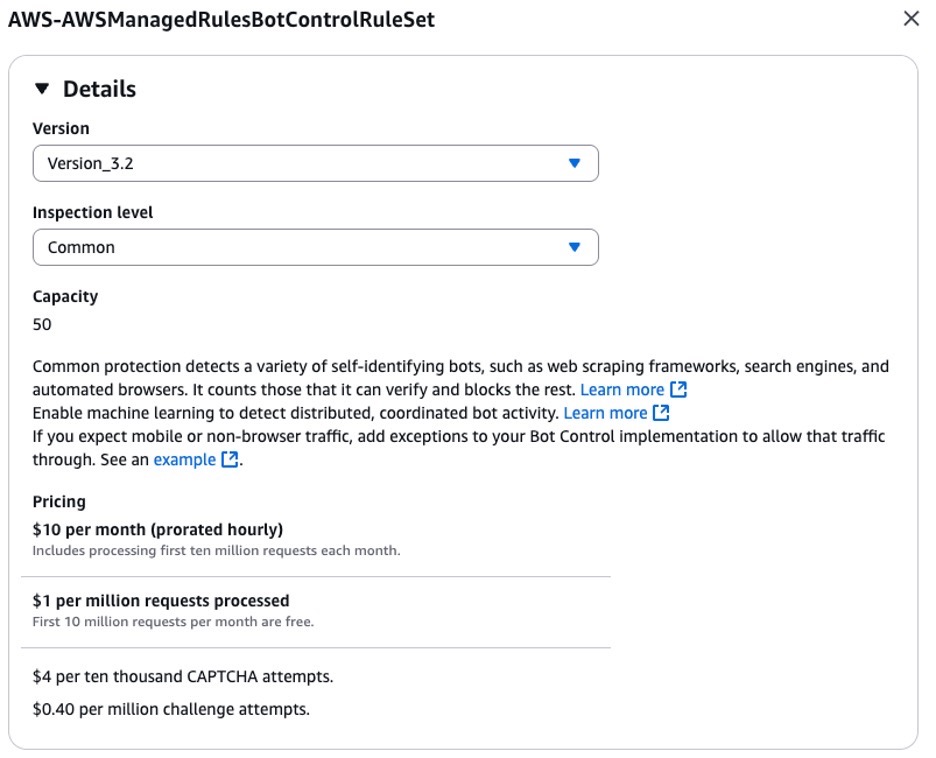
Figure 1: AWS WAF Bot Control rule group with Common inspection level and Version 3.2
After running the managed rule group for a few days, you can analyze the collected data. To view insights, open the AWS WAF and AWS Shield console and choose your AWS Region. Choose your protection pack and choose view dashboard. Navigate to the Overview section and choose the Bots option to see bot activity, detection, categories, and signals. This dashboard provides insights into bot activity on your application.
The following figure 2 shows an example of the Bot categories section. It displays a high volume of requests marked as ai - AllowedRequests. These are AI bots identified, but not blocked, by the CategoryAI rule. You may also notice other bots sending high volumes of requests.
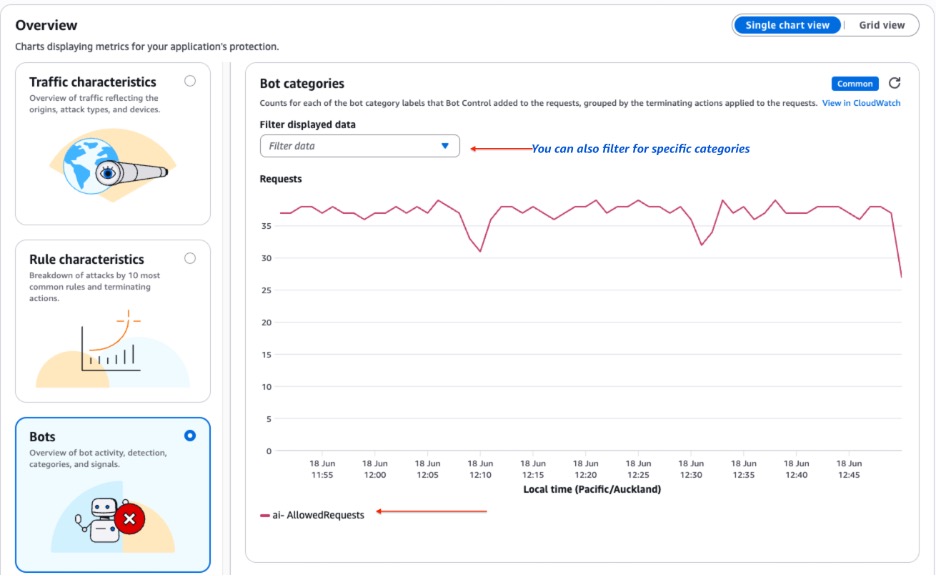
Figure 2: Traffic overview for CategoryAI rule detected by AWS WAF
Managing problems caused by AI bots
In the following sections, we go over different methods for managing problems caused by AI bots.
Stop AI bots early with robots.txt
Scenario 1: Stopping well-behaved AI bots early
A robots.txt file helps control bot access to your application. This simple text file is placed at your application’s root directory (/robots.txt). It uses a standard format to guide compliant bots about which parts of your application they can and cannot access. Although not all bots follow these rules, reputable bot operators respect properly configured robots.txt files. Open source projects such as ai.robots.txt offer a robots.txt with the latest AI-related crawlers that you can use to stop these bots before they start crawling your application.
If AWS WAF shows high request volumes from specific bots, then you can use robots.txt to stop overzealous and well-behaved scraping bots. This helps prevent them from affecting your DTO and application performance.
The following is an example to allow the Amazon Amazonbot to crawl /public URLs but not crawl /private URLs.
User-agent: Amazonbot
Disallow: /private/
Allow: /public/
Scenario 2: Managing how AI bots use your data
Bots from major tech companies serve dual purposes: they scrape your application once and use the data to index search and training AI models. You can permit these bots to crawl your application for search indexing, while still requesting that they do not use this data for training LLMs. The following are three examples showing how to prevent major bot operators from using your data to train LLMs:
1. Amazonbot: It uses the HTTP response header X-Robots-Tag: noarchive to signal that you don’t want this response to be used to train LLMs. You can implement this using a CloudFront response headers policy to add this header to every response from your application.
HTTP/1.1 200 OK
Date: Tue, 15 Oct 2024 08:09:00 GMT
X-Robots-Tag: noarchive
2. Applebot: You can request that Apple doesn’t use data from your application to train their machine learning (ML) models by adding an entry User-agent Applebot-Extended to your robots.txt. This still permits Apple to index your content for search. The following is an example entry to disallow Applebot-Extended from across your application:
User-agent: Applebot-Extended
Disallow: /
The User-agent directive in robots.txt serves a specific purpose. It matches patterns against a bot’s declared identity, which differs from the HTTP User-Agent header.
3. Googlebot: Similarly, Google allows you to disallow training Google’s ML models by adding the User Agent Google-Extended to your robots.txt:
User-agent: Google-Extended
Disallow: /
Some bot operators may not respect the robots.txt file so you must need to manage them using AWS WAF.
Using AWS WAF
Scenario 3: Managing AI bots that are driving poor performance and high costs
Aggressive AI bots scraping data from your application can degrade performance of your application and incur high DTO and compute charges. You can use the following techniques using AWS WAF and protect your application from bots that are not respecting robots.txt:
1. Manage self-identifying AI bots with AWS WAF Bot Control rule group with Common Inspection level:
We can block high volume AI bot requests by removing the Override all rules action you had previously set to Count in the AWS WAF Bot Control rule group with Common Inspection level. The CategoryAI rule now blocks these AI bots requests by default.
Other than AI bots under the CategoryAI rule, AWS WAF does not block bots that are common and verifiable. If you identify a verified bot, or category of bots, that are still driving high traffic volumes, then you must explicitly add a rule after the AWS WAF Bot Control rule group. This rule should block the specific bot (or class of bots as represented by a label namespace), as shown in the following figure 3.
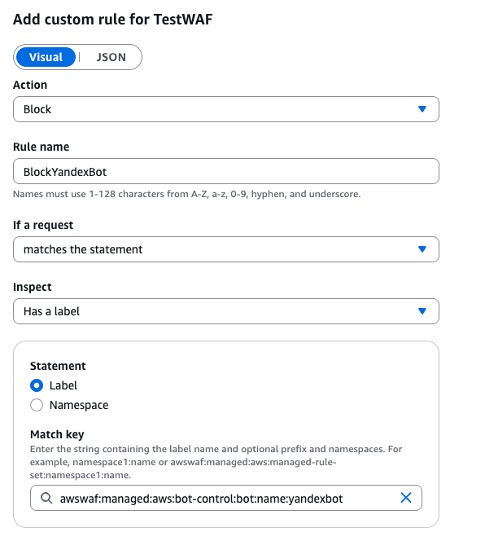
Figure 3: AWS WAF custom rule to block the yandexbot using labels
2. Slow down evasive scrapers:
Bots spoof their HTTP user agent headers to pretend they are well-known bots, or legitimate user clients. You can stop these bots overwhelming your application by using AWS WAF enhanced application layer (L7) DDoS protection and also AWS WAF rate-based rule. The DDoS rules and rate-limit rules protect your application from any source making high volume of requests including bots. To learn how to identify rate-based rule threshold and best practices on creating rate-based rules, refer to the post on the three most important AWS WAF rate-based rules.
3. Make evasive scrapers work for it:
The AWS WAF Challenge action runs a silent challenge in the client environment without requiring user interaction and is not intended to have a discernible impact on the user’s experience. The challenge requires a client to complete a computationally expensive task (proof of work). This approach intends to provide legitimate users with a seamless mechanism to validate their environment while increasing the cost for bot operators attempting to engage with your application.
The following figure 4 shows how to add a custom rule after the AWS WAF Bot Control rule group. This rule necessitates that users complete a challenge before proceeding, unless they are permitted/verified bots. Verified bots are identified by having a label in the namespace awswaf:managed:aws:bot-control:bot.
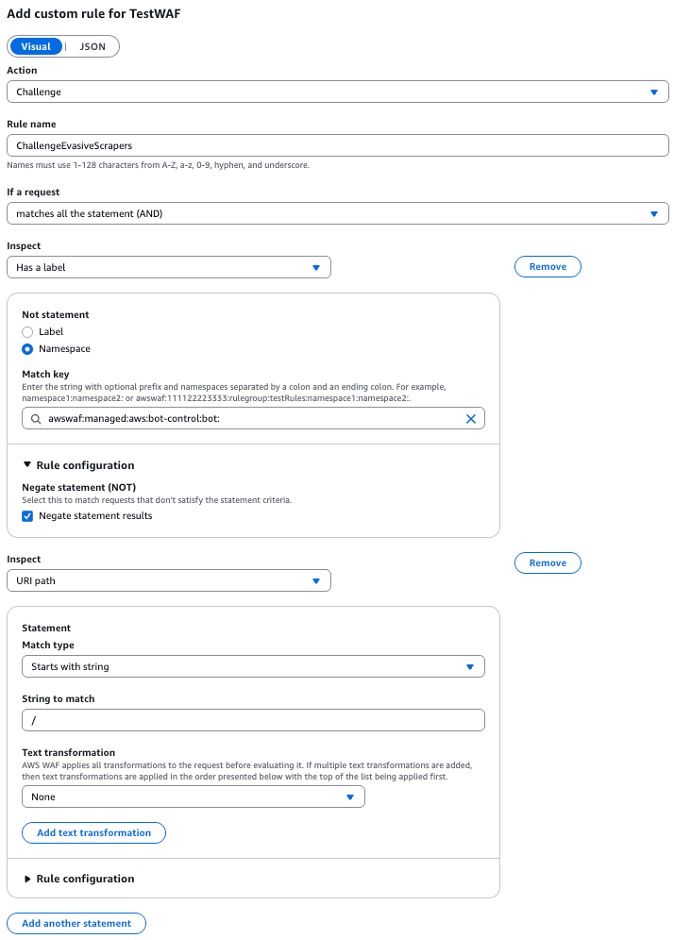
Figure 4: AWS WAF rule to force a challenge for all non-verified bot traffic
4. Use a honeypot to catch evasive bots:
Security Automations for AWS WAF includes a honeypot endpoint that lures bots crawling your application to an endpoint that no legitimate users or well-behaving bots access. The endpoint blocks these IPs as a way of limiting the impact of bots scraping your application.
Scenario 4: Managing unwanted automated/agentic AI bots
You can use the following techniques to manage agentic AI bots:
- AWS WAF Bot Control rule group with Common Inspection level: The
CategoryAIrule includes rules for well-identified AI agents such as Amazon Nova Act. Furthermore, theSignalNonBrowserUserAgent, andSignalAutomatedBrowserrules will block Playwright-style browser automation agents. - AWS WAF Bot Control rule group with Targeted Inspection level: This inspection level creates an intelligent baseline of traffic patterns. This uses fingerprinting techniques to help protect your application from agentic bots that mimic humans. Refer to the post detect and block advanced bot traffic for a guide on setting this up.
- AWS WAF CAPTCHA action: LLMs from major providers are trained to not solve CAPTCHAs. This will stop many agents from completing the requested interaction. Similarly to the previous Challenge technique, you can configure a rule with a CAPTCHA action to need certain requests for its completion. Refer to the post “Use AWS WAF CAPTCHA to protect your application against common bot traffic” for a guide to setting this up.
- Authentication (including biometrics): Ultimately, bots are going to continue to improve and evade mitigations. If you have strong requirements for human interactions, then consider using authentication including biometrics before continuing to engage. Refer to the post “How to use AWS WAF Bot Control for targeted bots signals and mitigate evasive bots with adaptive user experience” for a guide on driving adaptive user authentication when the interactions indicate possible bot traffic.
Conclusion:
AI bots create significant challenges through excessive scraping that degrades performance and increases costs, unauthorized use of content for AI training, and automated interactions that can range from annoying to malicious. By implementing the strategies discussed in this post, starting from basic robots.txt configurations to advanced AWS WAF Bot Control rules, rate limiting, and CAPTCHA challenges, you can protect from unauthorized data scraping, prevent performance degradation, and maintain control over how your content is used by AI bots.
Moreover, to remain updated with AWS WAF, refer to the AWS WAF Security Blog and what’s new with AWS Security, Identity, and Compliance.
Thank you for reading this post. If you have feedback about this post, then submit comments in the Comments section. If you have questions about this post, then start a new thread on AWS WAF re:Post or contact AWS Support.