Customers choose Amazon DynamoDB for its ability to deliver consistent, single-digit millisecond performance at any scale. It’s a serverless, fully managed, distributed NoSQL database that’s ideal for building modern, high-performance applications. A key part of unlocking the full potential of DynamoDB is designing your data model around your application’s access patterns. Although this approach might differ from traditional relational modeling, you can optimize for performance and scalability from day one. For those new to DynamoDB, this shift in mindset is an opportunity to rethink data design in a way that aligns directly with how applications query and update data.
As applications grow and scale, thoughtful data modeling in DynamoDB becomes increasingly important. Designing effective primary keys, choosing when to use global secondary indexes (GSIs), and deciding how and when to denormalize data all play a key role in building efficient, scalable systems. DynamoDB gives you the tools to optimize for performance and cost, but making the most of these capabilities requires understanding how they work together. In high-traffic scenarios with millions of users or sudden spikes in demand, these decisions can have an impact. Many development teams invest time upfront to get the data model right, knowing that this foundation sets them up for long-term success.
To help you move faster with greater confidence, we’re introducing a new DynamoDB data modeling tool, available as part of our DynamoDB Model Context Protocol (MCP) server. The DynamoDB MCP data modeling tool integrates with AI assistants that support MCP, providing a structured, natural-language-driven workflow to translate application requirements into DynamoDB data models. It’s backed by expert-engineered context that helps the latest reasoning models guide users through advanced modeling techniques.
In this post, we show you how to generate a data model in minutes using this new data modeling tool. By combining expert context with the latest reasoning models, this approach shortens the time it takes to develop an initial DynamoDB design. What previously took days or even weeks of research and iteration can now be accelerated to hours.
Solution overview
The DynamoDB MCP data modeling tool integrates with AI assistants that support MCP, including Amazon Q Developer, Kiro, Cursor, and Visual Studio Code. Setup instructions for supported tools are documented in the GitHub repository.
When you’re working with an AI assistant that supports MCP, the tool is invoked automatically when the topic of creating a DynamoDB data model comes up. For example, in Amazon Q you might say, “Help me design a DynamoDB data model,” and your AI assistant will automatically use the data modeling tool provided as part of the DynamoDB MCP server to initiate the process. In some cases, such as when using older or non-reasoning AI models, you might need to guide the assistant more directly by saying, “Use my data modeling MCP tool to help design a DynamoDB data model”. When the tool is triggered, it walks you through a step-by-step process inspired by how experienced DynamoDB architects approach data modeling.
The process begins with a structured workflow that captures your application’s access patterns and requirements. Using natural language conversation, it collects details about entities, relationships, and how your application reads and writes data. Each access pattern is documented along with estimated requests per second (RPS), which are key inputs for model optimizations and cost projections. These inputs are written to a markdown file named dynamodb_requirements.md in your project folder, which is continuously updated throughout the requirements phase. This file serves as a working reference to validate accuracy and fill in missing details before the design phase begins.
After the requirements are confirmed, a data model is generated and output to a markdown file named dynamodb_data_model.md. Although a high-level overview of the data model is described in the chat interface, this file includes detailed descriptions of tables, secondary indexes, and the reasoning behind each design choice. It also provides estimated monthly costs and flags access patterns that might be better suited to other AWS services, such as Amazon OpenSearch Service for text search or Amazon Redshift for analytics. Together, these two files form a clear, reviewable record of the entire process, designed to help you move quickly while following DynamoDB best practices.
To show the tool in action, we walk through designing a data model for a sample deals app, a mobile-first platform that reflects the scale and access pattern challenges common in modern applications.
Before we dive into the walkthrough, it’s worth highlighting that data modeling requires reasoning. In our experience, models with stronger reasoning capabilities, such as those in Amazon Q, Anthropic’s Claude 3.7 Sonnet and Claude 4 Sonnet, OpenAI’s o3 reasoning model, and Google Gemini 2.5 tend to produce the most effective results. We recommend using one of these options for optimal performance. We encourage you to share feedback about which models you use and the results you achieve.
Challenges with modeling for real-world scale
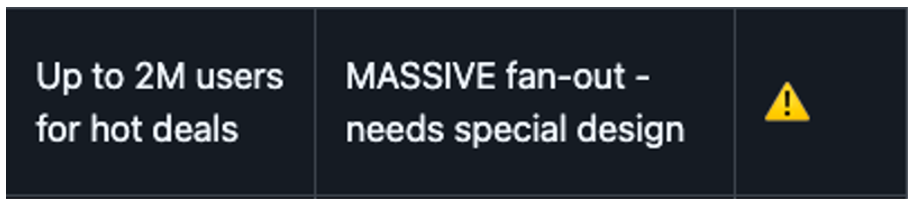
Our sample deals app serves over 2 million active users. During normal hours, the platform handles around 1,500 RPS, but during flash sales, traffic can spike to over 5,000 RPS in minutes and is still required to support diverse access patterns that each have varying performance requirements. Each day, 500–1,000 new deals are posted across 5,000 brands and 50 categories. When a popular deal drops, notifications are sent out to up to 2 million users, representing a classic fan-out pattern where one source event triggers many subsequent concurrent events—in this case, the one deal results in sending the same information to many consumers concurrently. This is an example of how to think about modeling for DynamoDB; you should think about your application holistically and design around it.
This kind of scale introduces several key data modeling challenges:
- Traffic volatility – Flash sales can triple load almost instantly. Traditional databases often struggle with this kind of variability, but the on-demand scaling in DynamoDB absorbs sudden spikes when the data model is designed with optimal partitioning in mind.
- Diverse access patterns – In our example, users can search in various ways such as by brand (1,200 RPS peak), category (1,800 RPS peak), and keyword (800 RPS peak). Each pattern has different performance characteristics and often benefits from a tailored indexing strategy.
- Massive fan-out – Popular flash sales send notifications to millions of users in parallel. Some brands have over 100,000 followers, and some categories exceed 500,000. Supporting that scale requires carefully designed write and read patterns that align with DynamoDB’s strengths.
These are the kinds of challenges the DynamoDB MCP data modeling tool is built to help you navigate, quickly and with confidence.
Requirements gathering
Let’s walk through an example to show how the data modeling tool helps address the challenges we outlined earlier, starting with the requirements gathering phase.
In the following example, we ask our AI assistant to help us design a DynamoDB data model. Because the assistant has access to the DynamoDB MCP data modeling tool, it automatically invokes it.
Next, we respond with a high-level description of the deals app we want to build. The conversation is natural and informal—you’re not constrained to answering questions in a specific format. Instead, we describe our requirements in our own words, and the tool handles the rest.
From there, the tool begins capturing requirements in a structured way. It creates a dynamodb_requirements.md file and starts logging each access pattern along with key metadata like request volumes and access frequency. We can keep this file open and watch it update in real time, making it straightforward to validate what’s being captured and correct any misunderstandings early. The following screenshot shows a portion of the requirements file where the tool begins documenting the identified access patterns.
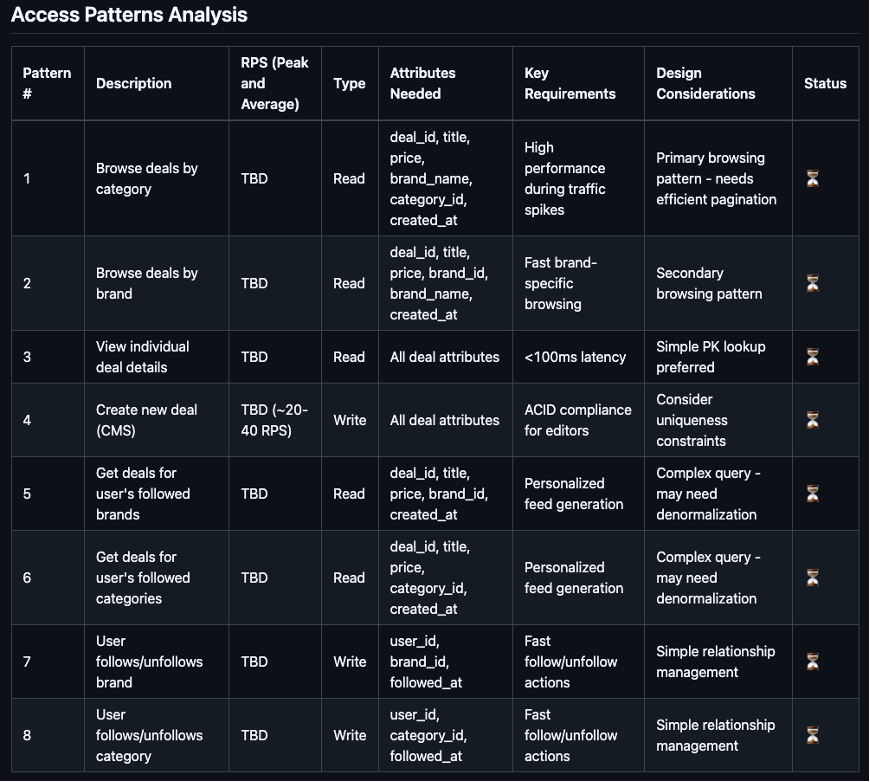
As the conversation continues, the tool follows up with questions tailored to our use case. These questions help clarify anything the AI assistant deems ambiguous or incomplete based on the data modeling context our new tool provides. For example, if you describe an access pattern to get users, it will ask whether you have an access pattern to create users, too.
The conversation then reaches where we describe the classic fan-out pattern we have: editors update featured deals by category throughout the day, an action that can trigger notifications to millions of users. In the following screenshot, the tool recognizes this as a large-scale fan-out pattern and flags it with a comment in the requirements file: “MASSIVE fan-out – needs special design.” As we see later, the special design is an asynchronous process using Amazon DynamoDB Streams and AWS Lambda. We’ve found that recent reasoning models are particularly good at catching subtle patterns like this.
The following screenshot shows an example in which a full-text search pattern is identified during requirement gathering. A note is made in the dynamodb_requirements.md file to offload this access pattern to OpenSearch Service. This is a valuable insight for developers who are new to DynamoDB and might not yet be familiar with how to handle patterns like these in a complementary architecture.

Comments like those shown in the previous two examples serve two purposes. They help you validate that your requirements are correctly captured, and they give the data modeling tool a way to resume where it left off if you pause and return later. In such cases, you might continue by saying “I started working on a DynamoDB data model. My requirements are in the dynamodb_requirements.md file located in this project folder. Help me continue designing my DynamoDB data model.”
Data model creation
After refining the requirements, we’re ready to generate a data model. The tool creates a second file in our project folder called dynamodb_data_model.md, which outlines the proposed table and index design. The following screenshot shows how each table is described, including key attributes and the rationale behind design decisions. Secondary indexes are documented in a similar way.

Toward the bottom of the dynamodb_data_model.md file, shown in the following screenshot, we find a breakdown of how each access pattern is supported, estimated monthly costs, and descriptions of the trade-offs or optimizations that were applied. In this case, you can see several optimizations directly address the scale and variability we described earlier.

From here, we can continue our conversation by exploring specific design elements in greater detail or incorporating new requirements to generate an updated model. This iterative workflow makes sure you’re never locked into a single pass—you can refine and adapt as needed. For next steps, you can ask your AI assistant to help you deploy and test the data model with sample data. For deployment and testing with sample data, you will transition from this specialized data modeling tool back to your AI assistant’s standard capabilities. Although we plan to introduce dedicated DynamoDB MCP tools to help deploy and load test data models in the future, your assistant will currently use its general knowledge to guide you through the deployment and testing process.
Looking ahead
The data modeling tool is just the beginning. It’s the first in a planned series of tools aimed at enabling natural language development with DynamoDB. By embedding expert guidance directly into AI coding assistants, we’re reducing the time it takes to go from idea to production-ready design, while improving both the quality and cost-effectiveness of what you build.
The DynamoDB MCP data modeling tool is open source, and we welcome contributions from the community. Your feedback and real-world use cases will help make it better for everyone.
You can contribute in the following ways:
- Design pattern contributions – If you’ve used DynamoDB in ways the tool doesn’t yet support, such as advanced indexing strategies or optimization techniques, we’d love to learn from you. Submit a GitHub issue with a detailed example, and if possible, include performance metrics or cost comparisons.
- Use case scenarios – Share your examples. Include the requirements you provided, the generated data model, the AI tool and model you used, and any suggestions for improvement. These examples help the tool evolve to support a broader set of scenarios.
- Bug reports and feature requests – If you find issues or have ideas for improving the workflow, use GitHub Issues to let us know. Be as specific as possible, especially when pointing out where the tool’s guidance could be more accurate or where additional validation might help.
Conclusion
In this post, we walked through how the DynamoDB MCP data modeling tool can accelerate one of the most challenging parts of building with DynamoDB: designing your data model. Using a high-traffic deals app as our example, we showed how the tool guides you step-by-step through requirement gathering and design, using natural language and backed by expert-level guidance that encodes years of knowledge from DynamoDB experts.
If you’re designing for scale, working with unfamiliar patterns, or just want to move faster with confidence, this tool can save you time and help you make better design choices from day one. Explore the GitHub repository to get started, try it out with your own use case, and join the growing community shaping the future of natural language development on DynamoDB. We look forward to your feedback, ideas, and contributions.